Design and Architecture
This document aims to describe the architecture of Alpa and explain several core concepts and compilation passes introduced by Alpa at a high level. It provides an overview of Alpa’s architecture, including core terms and componenents introduced by Alpa. In Alpa Compiler Walk-Through, we further show the workflow of Alpa using an MLP example.
You are recommended to read the the following materials as well:
Alpa paper (OSDI’22)
Overview
The figure below shows a high-level diagram of Alpa’s architecture.
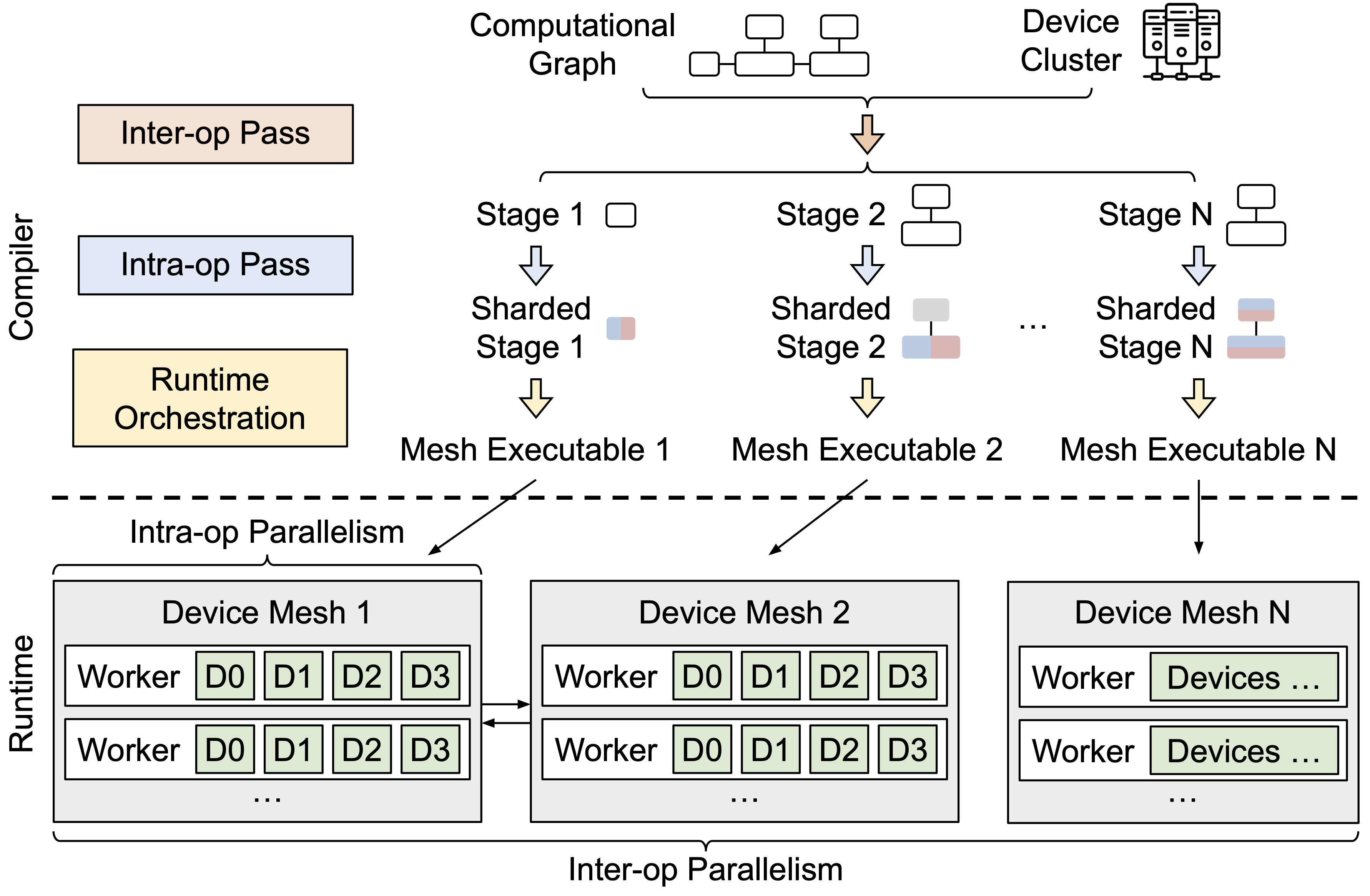
Figure 1: Alpa architecture diagram.
Like many existing machine learning compilers, Alpa parallelizes the ML computation in two steps: a compilation step, followed by a runtime step.
In the compilation step, Alpa takes a model description, in the form of a computational graph, and a device cluster as inputs, and performs a few compilation passes and optimizations to generate a model-parallel execution plan, which is custom-made for the model and cluster. Alpa then generates binary executables based on the training code and parallel execution plan, for each parcipating compute device in the cluster. In the runtime step, Alpa orchestrates the parallel execution of these executables on the cluster.
Compilation
Before we start introducing the compilation architecture, we bring in two important concepts introduced by Alpa. Unlike many existing distributed ML training systems, Alpa views existing ML parallelization approaches into two orthogonal categories: intra-operator parallelism and inter-operator parallelism. They are distinguished by the fact that if the parallelism approach involves partitioning any computational operator of the model along one (or more) tensor axis. Some examples falling into the two categories are listed below:
Intra-op parallelism: data parallelism, Megatron-LM’s tensor model parallelism, operator parallelism such as those in ToFu and FlexFlow, etc.
Inter-op parallelism: device placement, pipeline parallelism and their variants.
For a deeper dive into what these two classes of parallelism entail, please read the documentation about our rationale.
This new view of ML parallelization techniques is the core part that drives Alpa’s design: Alpa unifies existing ML parallelization methods following this view by realizing them in a two-level hierarchy shown in Figure 1. At the upper level, Alpa designs a set of algorithms and compilation passes, which we call inter-op pass to generate parallel execution plan corresponding to all inter-op parallelisms; at the lower level, Alpa designs another set of algorithms and compilation passes, which we call intra-op pass, to generate the parallel execution plan mapping to all intra-op parallelisms.
Alpa can guarantee the plan generated at each individual level is locally optimal. Once the two-level plans are generated, Alpa runs a third pass runtime orchestration pass. In this pass, Alpa applies the plans on the input computational graph, performs some post-processing, and finally compile the original, single-node graph into parallel executables. It then sends the parallel executables to devices on the cluster.
Important concepts
Understanding the following concepts are necessary to understand what each pass is precisely doing during compilation.
Computational graph
Like many machine learning compiler systems, Alpa represents the model computation as a static computational graph. For now, this computational graph is first extracted from the user code and expressed using the JaxPR intermediate representation, and then lowered to the XLA HLO representation.
Device cluster
Alpa runs on a cluster of compute devices, managed by Ray. For example, a cluster of four AWS p3.16xlarge nodes, with 8 GPUs on each node, form an 4x8 device cluster, illustrated in Figure 2 below. We also call this device cluster the cluster mesh.
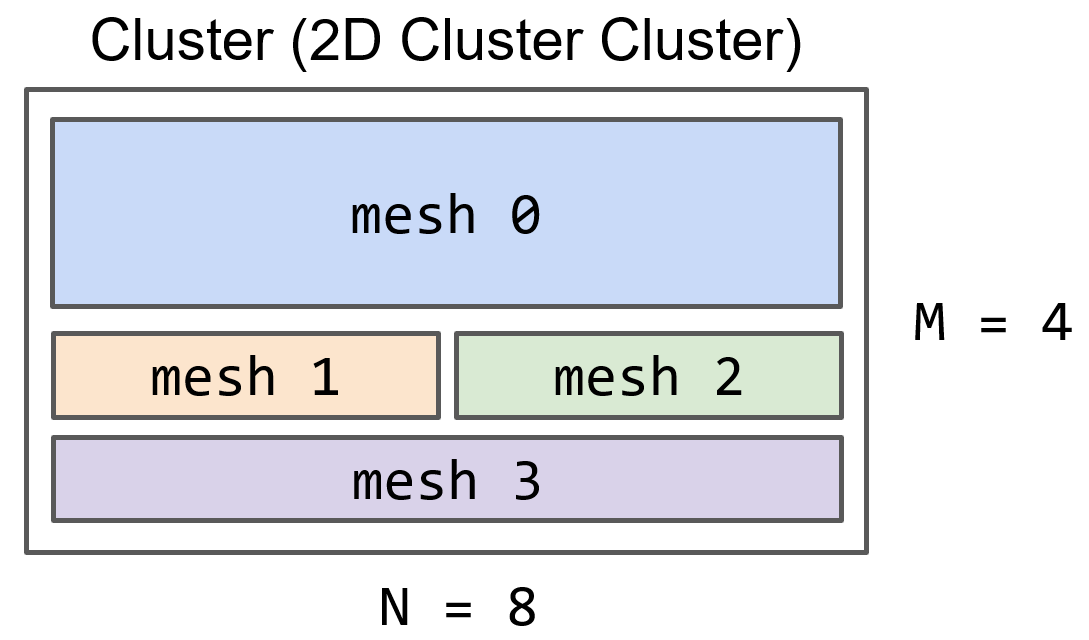
Figure 2: an M x N cluster mesh.
Device mesh
Alpa’s inter-op compilation pass will slice the cluster mesh into multiple groups of devices. Each group might contain a number of devices with high communication bandwidth, such as NVIDIA NVLink. We call each group of devices a device mesh. Figure 2 shows how a cluster mesh is sliced into 4 device meshes.
Worker
Each device mesh might consist of partial or full devices from a single node or from multiple nodes. Alpa uses a worker to manage multiple devices from a node; hence a device mesh might contain multiple workers, each mapping to a process that manages multiple devices on a node. For example, Figure 3 shows a mesh, consisted of 2 workers, and each worker manages 4 devices. The workers are implemented as Ray actors.
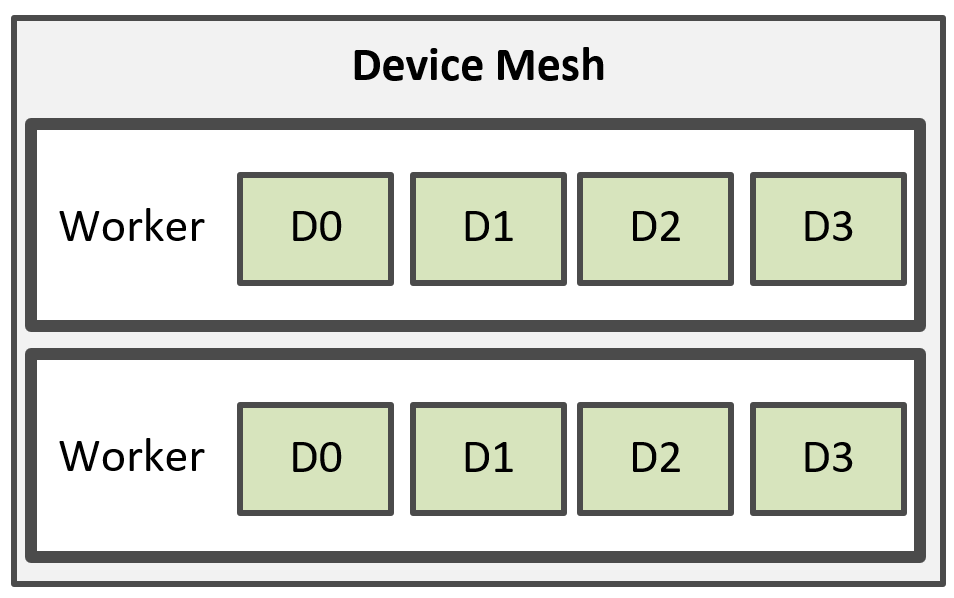
Figure 3: A mesh is consisted of multiple workers managing devices.
Stage
Alpa slices the input computational graph into multiple, adjacent subgraphs. We call each subgraph a stage.
Resharding
# TODO
Compilation Passes
With the above concepts, we now explain what each compilation pass is exactly doing.
Inter-op Pass
Inter-op pass slices the computational graph into multiple stages and the cluster mesh into multiple smaller device meshes; it then assigns each stage to a mesh. Alpa generates the slicing and assignment scheme optimally using a dynamic programming algorithm to minimize the inter-op parallel execution latency.
Intra-op pass
Intra-op pass looks at each <stage, mesh> pair generated by the inter-op pass, and generates the optimal intra-op parallelism execution plan for this stage to run on its assigned mesh.
Runtime Orchestratoin pass
The runtime orchestration pass looks at the pairs of stages and meshes generated by the inter-op pass, and the intra-op parallelism strategy generated for each <stage, mesh> pair by the intra-op pass. It analyzes their data dependency, and tries to fullfills some requirements before runtime. These requirements include:
Communication: sending a tensor from a stage to its next stage. When the two stages have different intra-op parallelism execution plan, the tensor might be sharded differently on two meshes. In that case, cross-mesh resharding is required. Alpa’s runtime orchestration pass will try to generate the optimal scheme on how to communicate the tensors between two meshes.
Scheduling: Alpa’s runtime will also compile and generate static scheduling instructions for pipelined execution of all stages, to minimize scheduling overheads at Runtime.
These three compilation passes are implemented on top of XLA and GSPMD. Despite the compilation passes for distributed execution, XLA and GSPMD additionally perform some other necessary optimizations to improve the single-device execution performance.
Runtime
Alpa implements a runtime to orchestrate the inter-op parallel execution of different stages on these meshes. For each stage, Alpa uses the GSPMD runtime to parallelize its execution on its assigned device mesh, following the intra-op parallelism execution plan generated by the intra-op pass.